Divorce Predictors
Models Used
The data set comprised 54 features with Likert scale responses (0=Never, 1=Seldom, 2=Averagely, 3=Frequently, 4=Always). We used 3 classification algorithms - Logistic Regresssion, Support Vector Machines (SVM), and K Nearest Neighbors (KNN) - to make predictions and determine prediction accuracy.
After making predictions using all features, we identified the top five features* using feature importance in the Random Forest Classifier. We then repeated the process using just these features to see how this affected the accuracy of our predictions.
The top five features, in order of importance:
9. I enjoy traveling with my wife.
18. My spouse and I have similar ideas about how marriage should be.
40. We’re just starting a discussion before I know what’s going on.
11. I think that one day in the future, when I look back, I see that my spouse and I have been in
harmony with each other.
20. My spouse and I have similar values in trust.
*In the process of gathering predictions on all factors for the SVM model, the featur importance function identified a new set of top 5 questions (18, 40, 16, 17, 11), though the Classification Report remained identical.
Logistic Regression
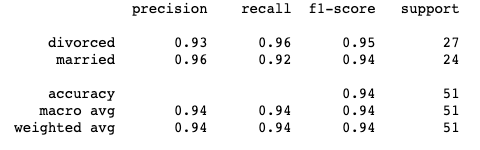
Classification Report for predictions looking at all factors
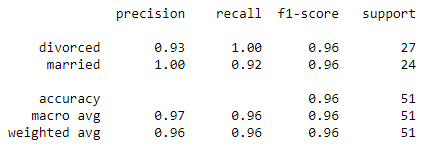
Classification Report for predictions looking at Questions 2, 6, 11, 18, 26
SVM
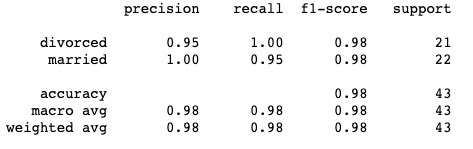
Classification Report for predictions looking at all factors
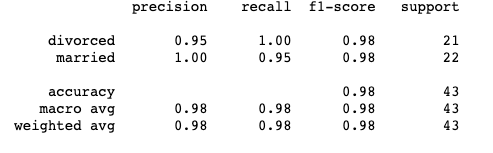
Classification Report for predictions looking at Questions 2, 6, 11, 18, 26
KNN
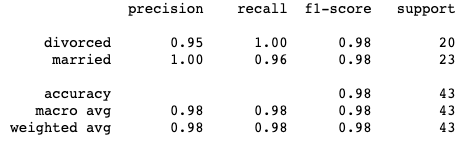
Classification Report for predictions looking at all factors
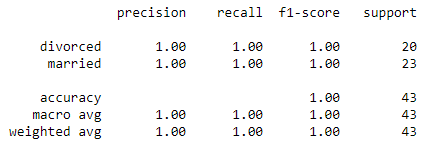
Classification Report for predictions looking at Questions 2, 6, 11, 18, 26